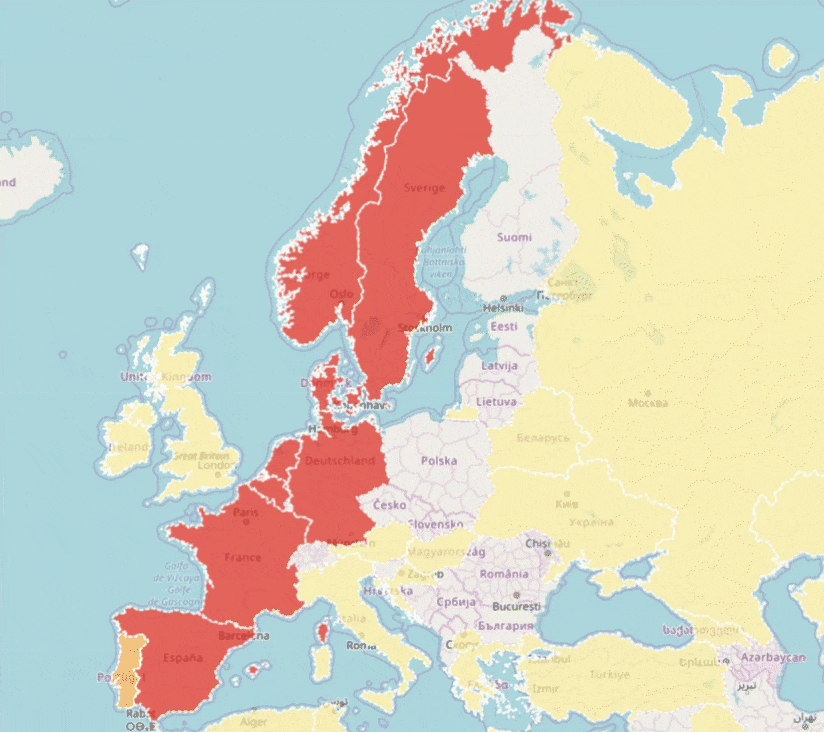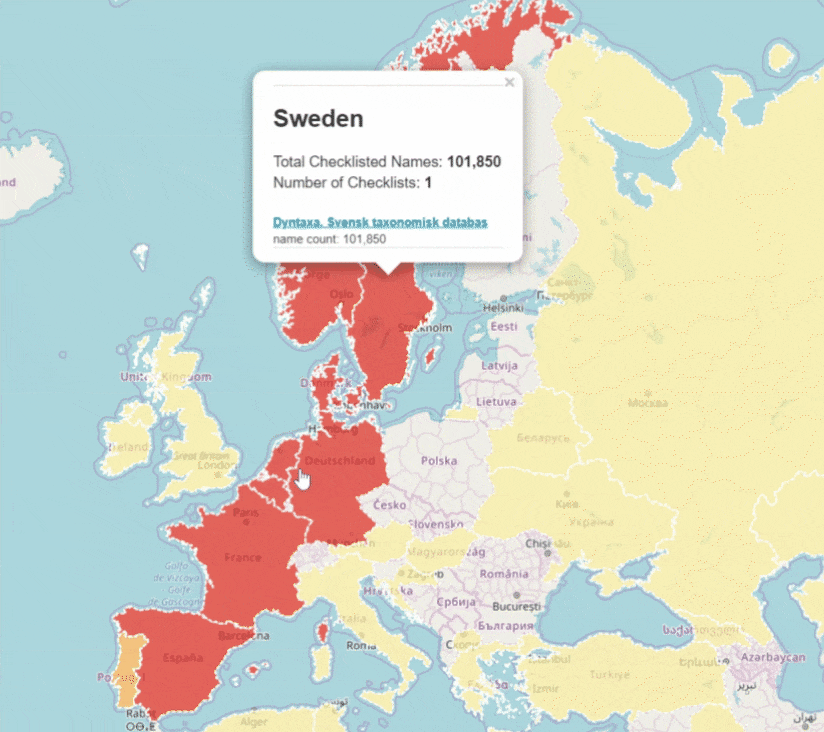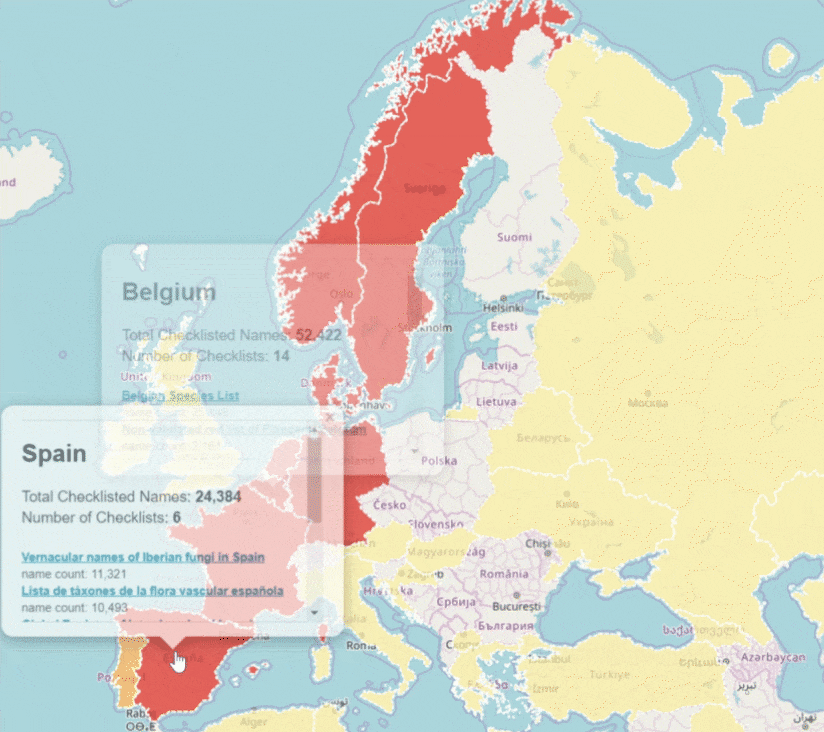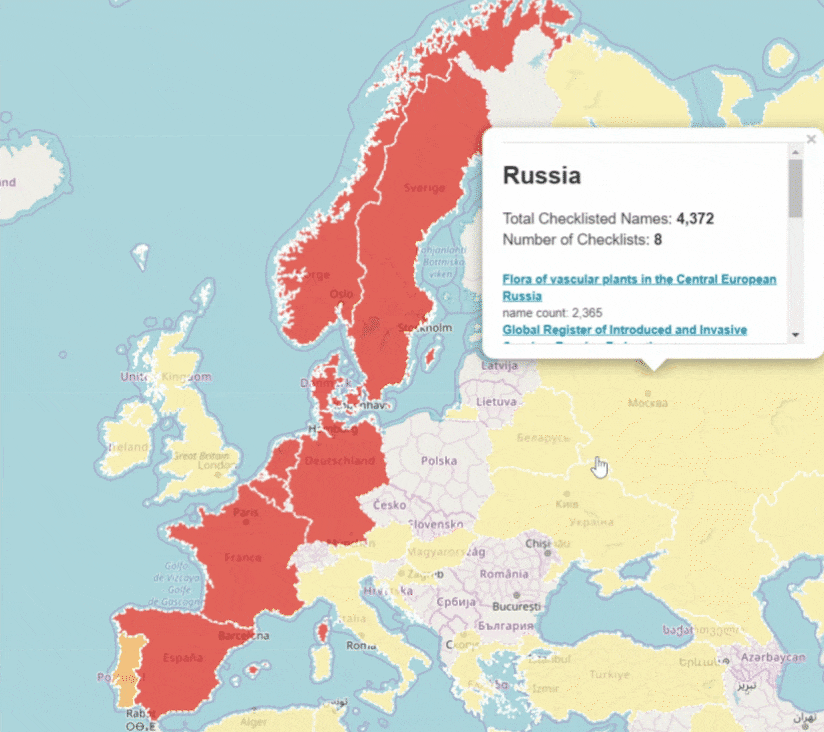
GBIF attempts to improve identifier stability by monitoring changes of occurrenceIDs
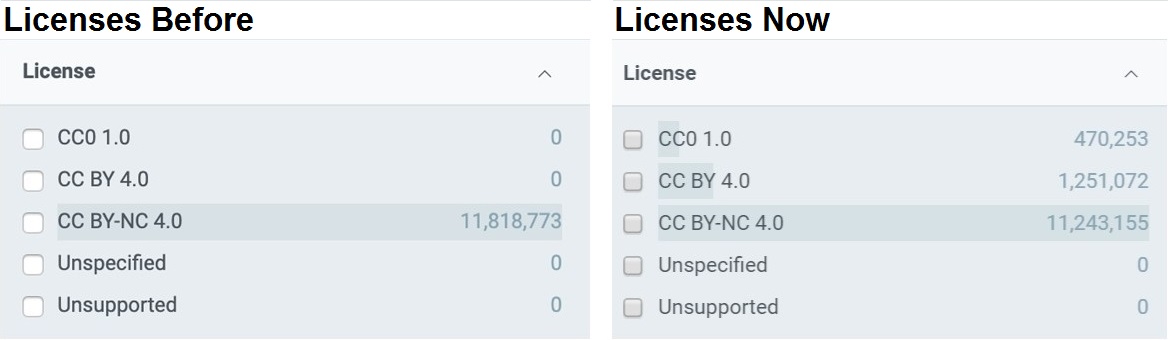
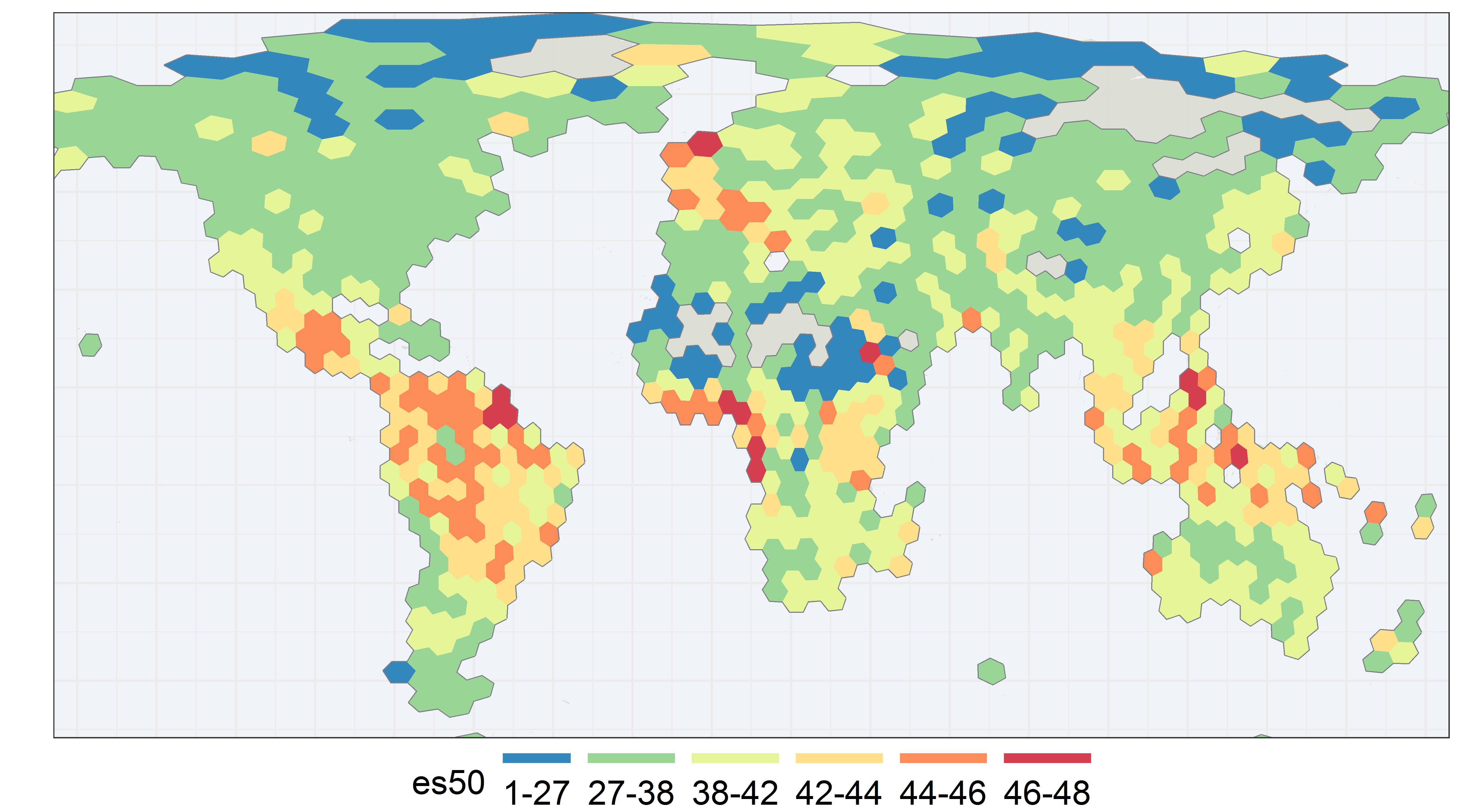
Since 2022, GBIF has been monitoring changes of occurrenceIDs in datasets to improve the stability of GBIF identifiers. We pause data ingestion when we detect more than half of occurrence records in the latest version have different occurrenceIDs from the previous version (live on GBIF.org). This identifier validation process automatically creates issues on GitHub and GBIF helpdesk will contact the publishers to verify the changes of occurrenceIDs.
Our aim in this process is to minimize the changes of GBIF identifiers and to support the needs for citations and data linking.