Big National Checklists
- Big 15-300K total names
- Medium 5-15K total names
- Small 0-5K total names
Here I plot the total names in checklists published on GBIF linked to a single country. A checklist dataset is a term for any dataset that contains primarily a list of taxonomic names. National species checklists are lists of species recorded from a country usually through some organized effort. GBIF has published a guide on best practices for making national checklist datasets, which advises making national checklists as big as possible.
Big national lists
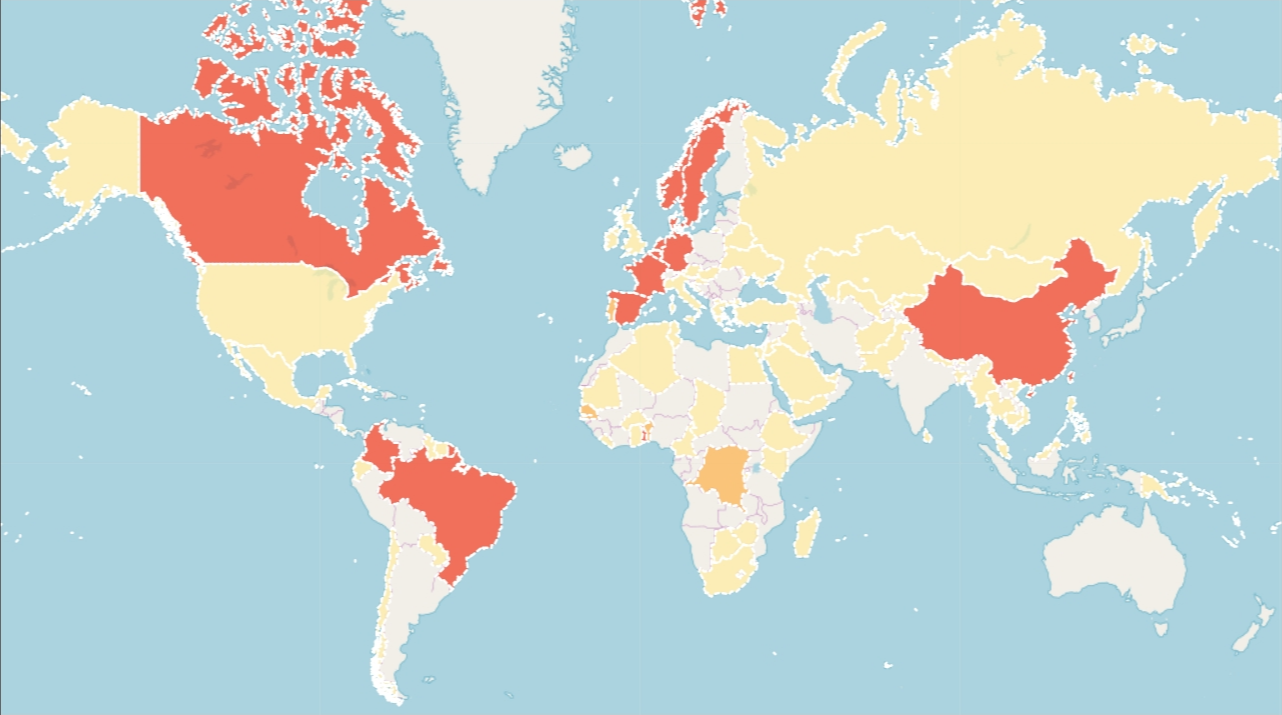
Only a few countries have large national checklists over 15,000 names.
| 1. France | 250k |
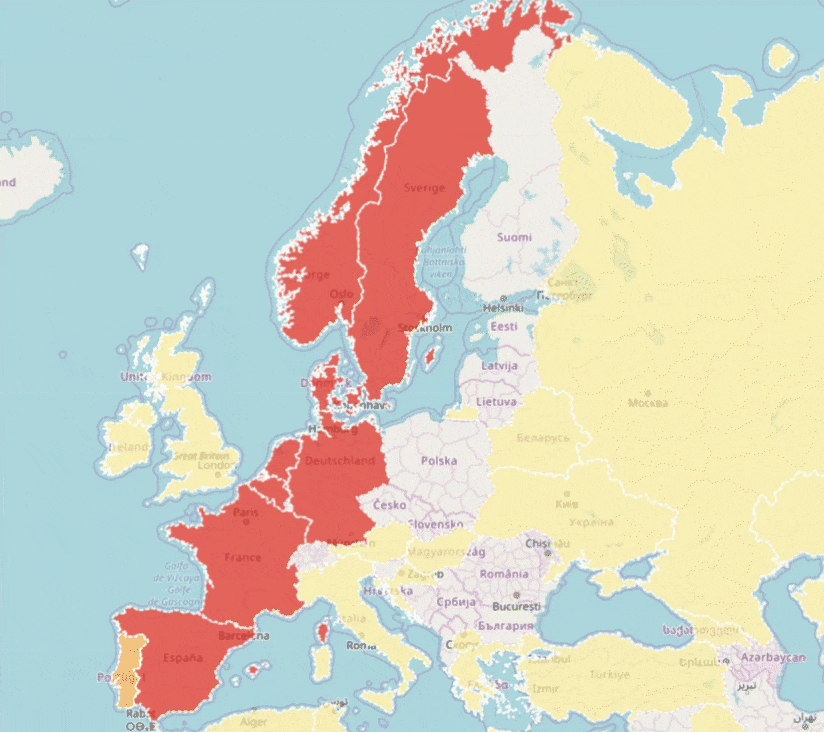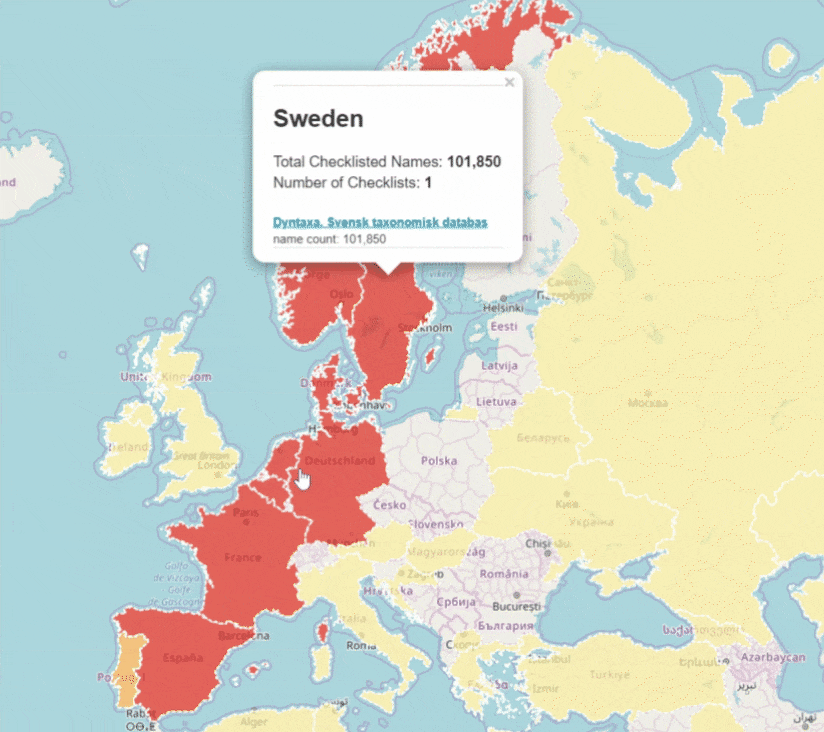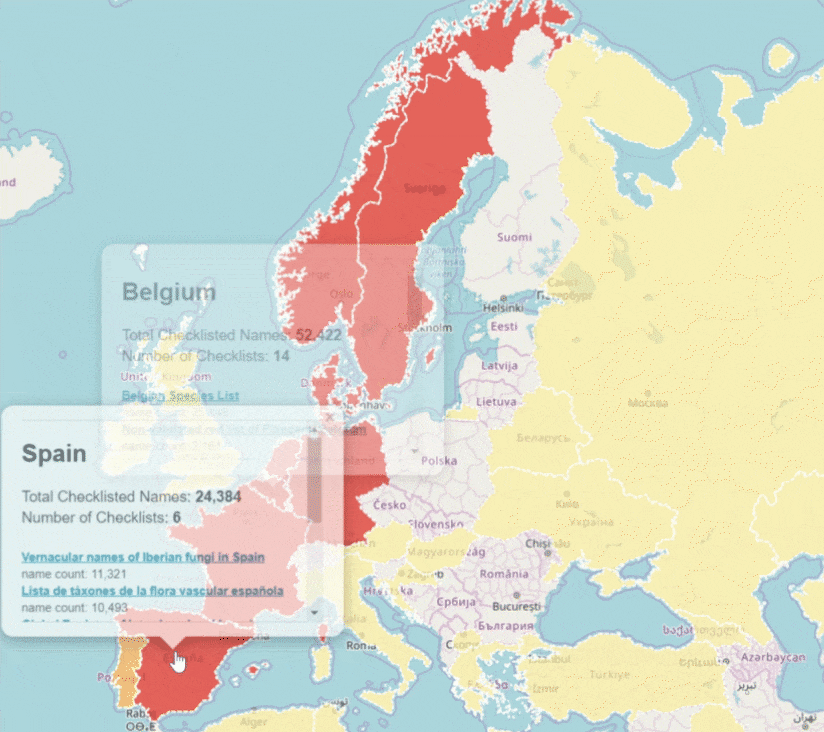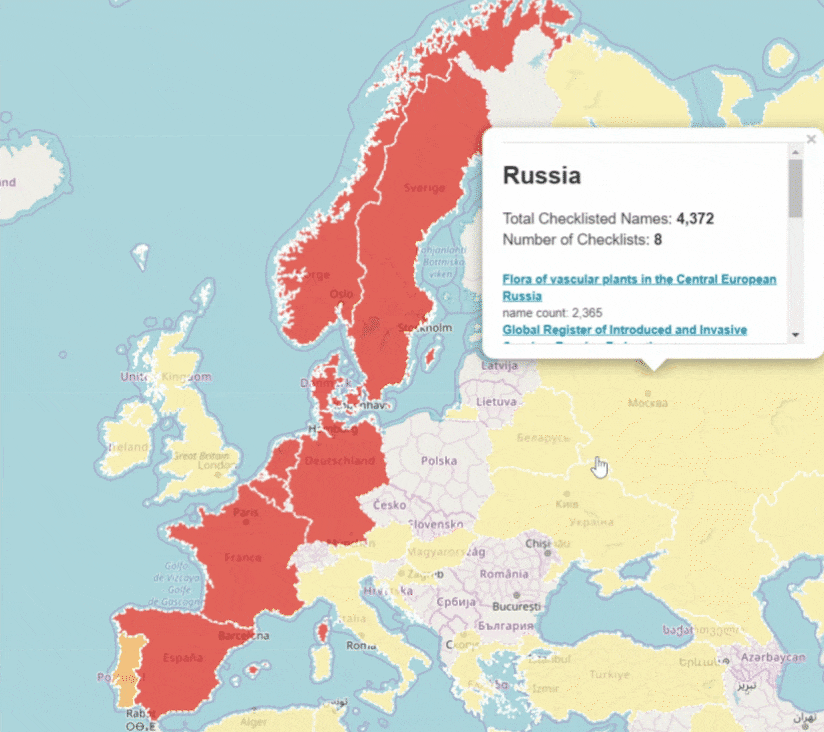
| 2. Sweden | 100k |
| 3. Norway | 100k |
| 4. Columbia | 73k† |
| 5. Netherlands | 65k |
| 6. Brazil | 64k |
| 7. China | 76k |
| 8. Taiwan | 66k |
| 10. Germany | 67k† |
| 11. Belgium | 52k |
| 12. Canada | 29k† |
| 13. Togo | 17k† |
†published in mulitple checklists
No big checklists in USA, Australia, Great Britain…
Even though the USA, Australia, and Great Britain share with GBIF massive amounts of occurrence records (>600M records combined), they do not seem to publish many checklists.
This could be for multiple reasons:
- Perhaps checklists exist but are simply not published on GBIF.
- Alternatively, the “checklists” in these countries could be included in occurrence datasets.
- Or the countries feel that occurrence datasets are superior and sufficient.
- Or I have missed the checklist. (You can comment if you think I have missed a checklist)
Austrailia does not publish anything classified as a checklist on GBIF, but the Atlas of Living of Austrailia serves as default checklist of Austrailia.
The Atlas of Living Australia (Atlas) contains information on all the known species in Australia aggregated from a wide range of data providers: museums, herbaria, community groups, government departments, individuals and universities.
The United States does not have any large checklists on GBIF, but it does publish many occurrence datasets with wide taxonomic coverage.
South Africa’s large plant dataset BODATSA is published as an occurrence dataset but could probably used as a very good checklist of South African plants.
Switzerland publishes several occurrence datasets that could probably be used as checklists.
New Zealand also publishes a national checklist, but (as of the writing of this post) the names have never be been ingested into GBIF.

GBIF has recently implemented a species download utility, so generating “a national checklist” derived from occurrences is now very easy. Although this is probably not the best way to make a checklist.
Not many checklists where we might want them the most
Most of Asia is occurrence and checklist-poor.
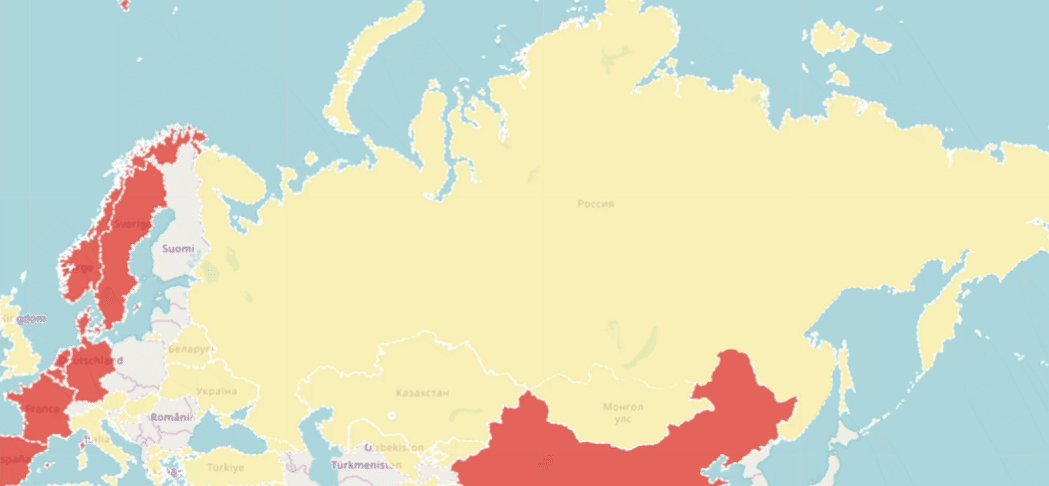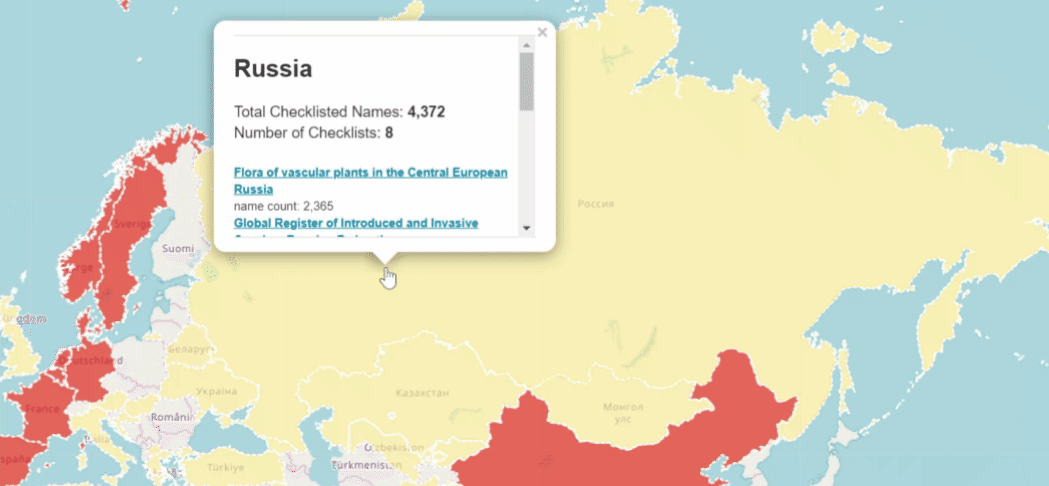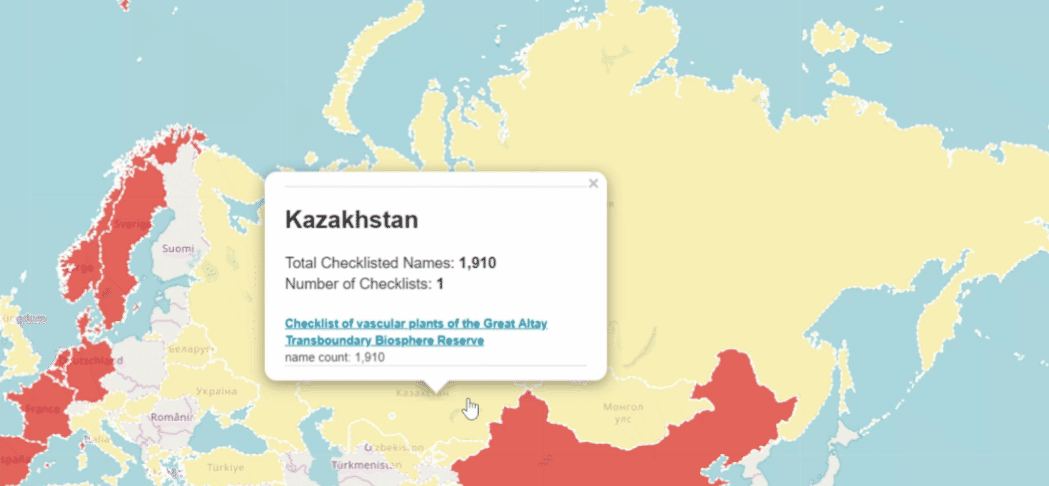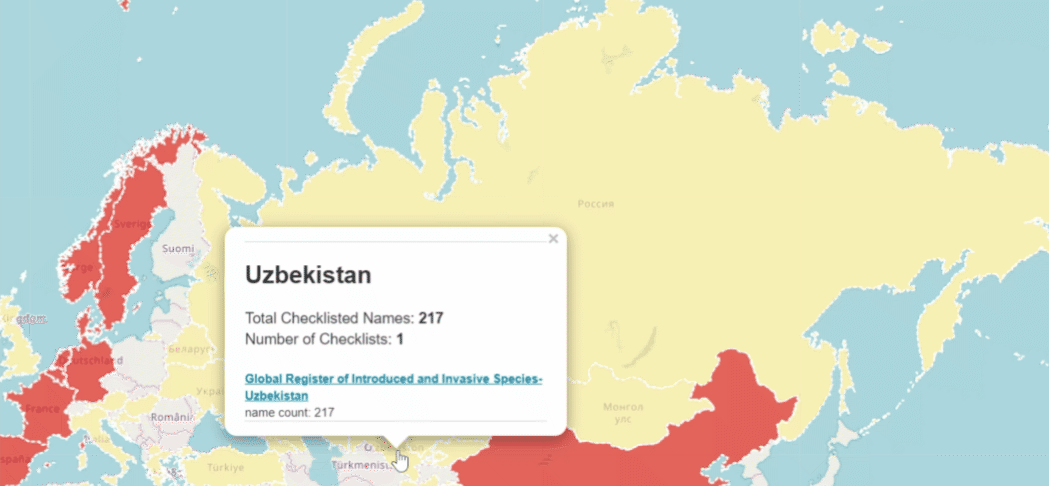
Will occurrence datasets become the default checklists?
Creating national checklists is a big job. They are valuable, but governments and foundations with limited budgets might find creating and curating occurrence datasets more worthwhile. I personally fear the cost/benefit of checklists might make them too expensive to create for the places where we might want to have them the most.
Manual tagging of checklist data
GBIF currently has 27,000 things it calls checklist datasets. Even after filtering out 200 datasets from global publishers, this still leaves a large amount of datasets needing to be tied to a region.
Checklists are not always tied to any region in a consistent way. There is a standard way to link a checklist to a country code or region that I did not know about before starting this post. It is through the distribution extension, which has a countryCode field. 64% of the checklists I tagged have filled in the extension. The remaining untagged datasets have not filled in this extension.
In order to reduce the size of the tagging job, I decided only to tag datasets with more than 500-1000 species names. I have only tagged checklist so far that are tied to one country and ignored checklists that might be regional like Fauna Europaea. Fauna Europaea incidentally has very good polygon-linked data. Unfortunately, Fauna Europaea has not filled in the distribution extension.
Using this biggest-first stategy, I have been able to tag around 85% of total names in checklists (not in global lists), tagging around 600 datasets with country codes.
I have also tagged any dataset that has filled in the distribution extension or geographic scope information in the meta-data. What has been left un-tagged are a large amount small checklists extracted by plazi.org. These untagged datasets are usually newly discovered species lists from the plazi taxonomic treatments database.
All of the datasets presented in the map above are now tagged in the registry. The following api call will get you all datasets tagged with a country code.
http://api.gbif.org/v1/dataset?machineTagNamespace=checklistCountryCode.jwaller.gbif.org&limit=600