Derived datasets
You’ve finished an analysis using GBIF-mediated data, you’re writing up your manuscript and checking all the references, but you’re unsure of how to cite GBIF. If you Google it, you’ll probably end up reading our citation guideslines and quickly realize that GBIF is all about DOIs. Datasets have their own DOIs and downloads of aggregated data also have their own DOIs.
But maybe you didn’t download data through the GBIF.org portal. Maybe you relied on an R package like rgbif or dismo that retrived data synchronously from the GBIF API? Maybe a grad student downloaded if for you? Maybe you accessed and analyzed the data using a cloud computing service, like Microsoft Azure or Amazon Web Services? In any case, which DOI do you cite if you don’t have one?
Introducing Derived Datasets
To overcome this problem and any other situation in which a user wishes to assign a DOI to a subset of GBIF-mediated data, for which a DOI doesn’t exist or isn’t representative, we introduce the Derived Dataset. Simply put, a derived dataset is a citable record (with a unique DOI) representing a dataset that doesn’t exist as a conventional, unfiltered GBIF.org download. So what does it take to create one and how do you do it?
As a minimum you’ll need two things: 1) a GBIF.org account and 2) a list of contributing (parent) datasets with record counts—i.e. how many records did each dataset contribute. If your data contains all available fields from GBIF, you’ll need to summarize it based on the datasetKey field (What if you don’t have this field?). There are numerous ways of doing this in R, using Excel, datamash, and other similar tools. But in the end you’ll want to have a list like this:
<datasetKey 1> <# records>
<datasetKey 2> <# records>
<datasetKey 3> <# records>
etc.
Secondly, in the interest of reproducibility, make sure to deposit your dataset somewhere publicly accessible (e.g. Zenodo). When you’re ready, go to the derived dataset tool and fill it out as shown below.
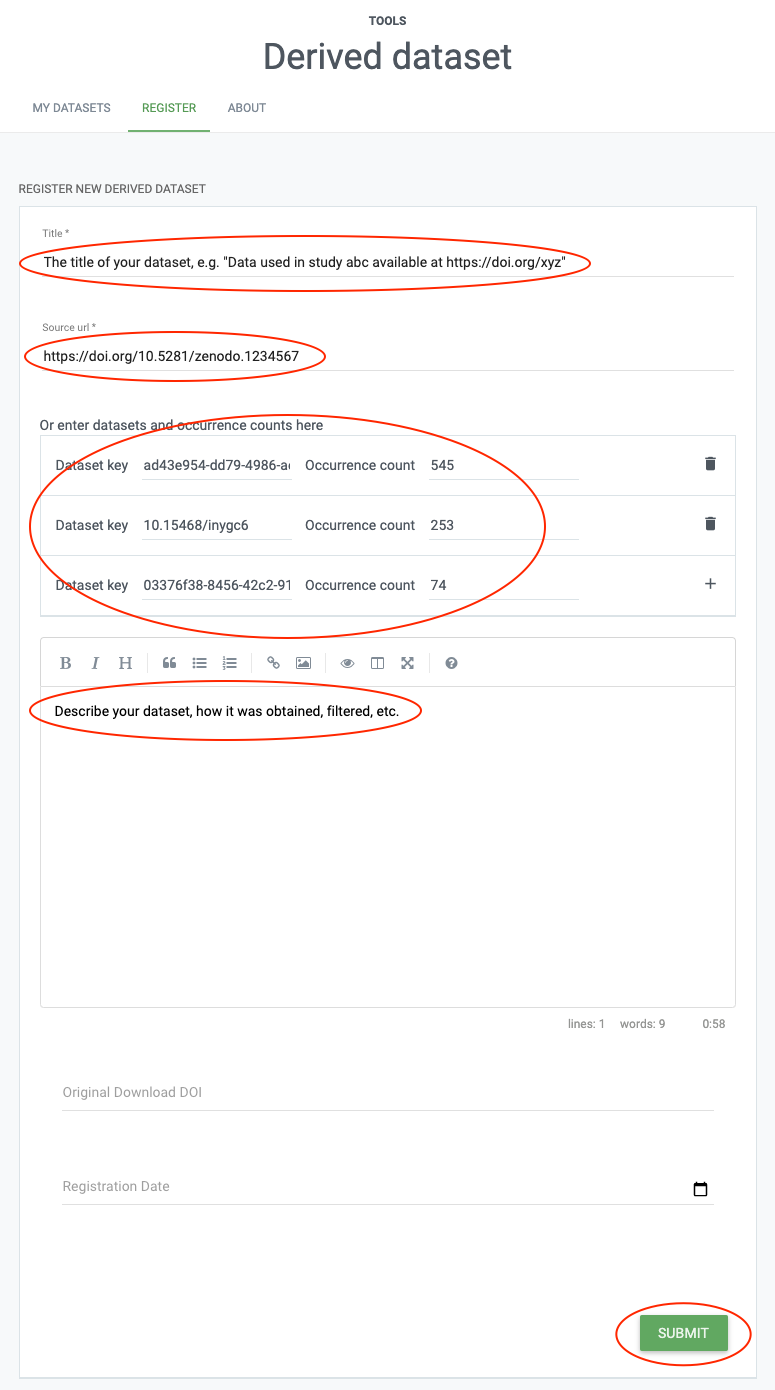
All it takes is
- a title,
- the URL of where your dataset is deposited,
- a list of datasets (by datasetKey or DOI) with record counts either as a CSV file or filled in on-screen, and
- a description of what the dataset is and how it came together.
That’s it!
The form also has two optional fields: one for specifying an original download DOI if the derived dataset represents a filtered version of that download, and a registration date, if, for someone reason you wish the derived dataset to be registered in the future rather than immediately (e.g. embargoed materials).
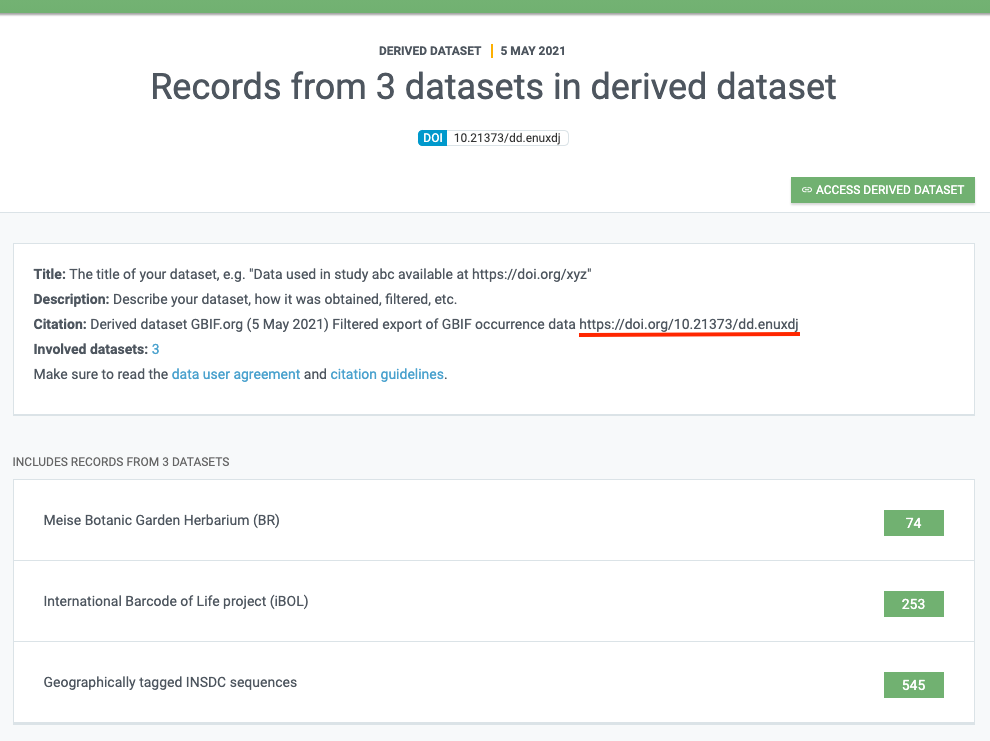
Hit SUBMIT and once the registration is complete, you can click the GO TO DATASET button to see the result and get the DOI.
You’ll notice that there’s a suggested citation string there as well. You’re welcome to change this to your liking as long as you keep the DOI.
My data doesn't have the datasetKey field
If your data does not have this field, you may be able to use the occurrence key instead and look up the parent dataset, i.e. from
https://api.gbif.org/v1/occurrence/<occurrence key>
get value of the field datasetKey, e.g.,
"datasetKey": "cd6e21c8-9e8a-493a-8a76-fbf7862069e5"
Note, that this method requires that the occurrence records are still available in GBIF. If a few are missing, that’s ok. If you are able to successfully identify the parent datasets of most of the occurrences in your dataset, you’re still good to go. It’s better to accurately cite and credit some of the data publishers whose data you used than none at all!