How to choose a dataset class on GBIF?
If you are a (first time) publisher on GBIF and you are trying to decide which type of dataset would best fit your data, this blogpost is for you.
All the records shared on GBIF are organized into datasets. Each dataset is associated with some metadata describing its content (the classic “what, where, when, why, how”). The dataset’s content depends strongly on the dataset’s class. GBIF currently support four types of dataset:
- Resource datasets (e.g. metadata-only datasets)
- Checklists
- Occurrence datasets
- Sampling-event datasets
These classes are described in detail on our Dataset classes page along with links to examples and documentation. As mentioned on this page:
The four classes of datasets supported by GBIF start simply and become progressively richer, more structured and more complex.
In other words, the distinction between the different classes is not always very obvious. This is why I tried to put together a quick guide to help you choose the class that fits best your data.
Five questions to help you decide
The first step to help you choose a dataset type is to ask yourself the right questions. The five questions below might not cover every single case but I hope it can help most of you:
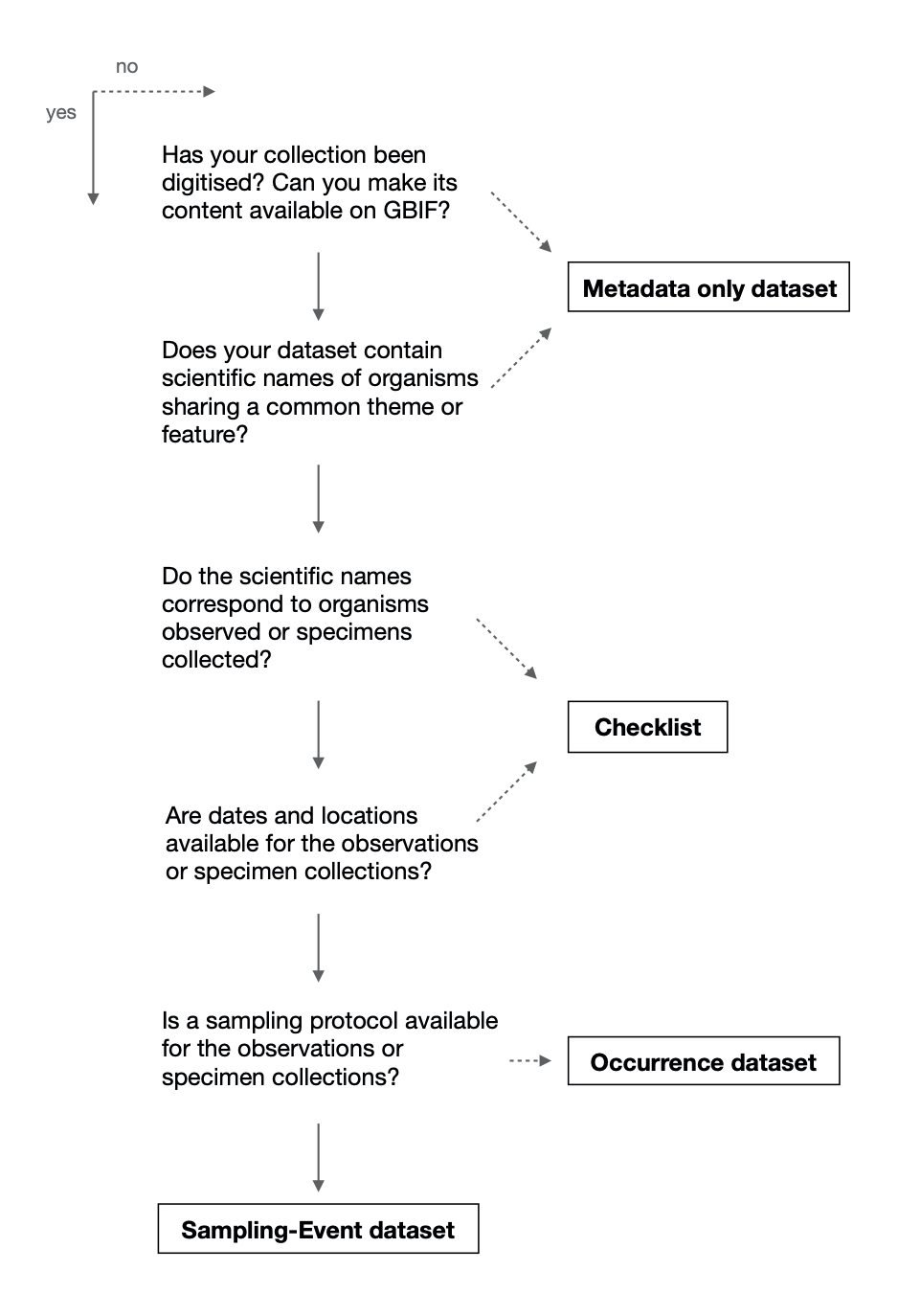
Note that this is a little bit more complex than that when extensions are taken into account. For example, checklists can contain occurrences. However, I won’t dive into the details here as this could be the topic of another blogpost.
Data quality requirements associated with each class
The data quality requirements describe what you should provide for each dataset class. It doesn’t mean that the data won’t be indexed if some values are missing, but these requirements summarize what can be considered meaningful information for each class.
These requirements are detailed on our Data quality requirements pages. I strongly suggest that you consult these pages before sharing data on GBIF.
That being said, the schema below summarizes the information required for each classes:

Sampling-event datasets
This type of datasets contain the most information and is therefore the most valuable for the community. We have an introduction page on the topic. If you are considering publishing sampling-events, this is a good place to start but I will make an even shorter introduction here.
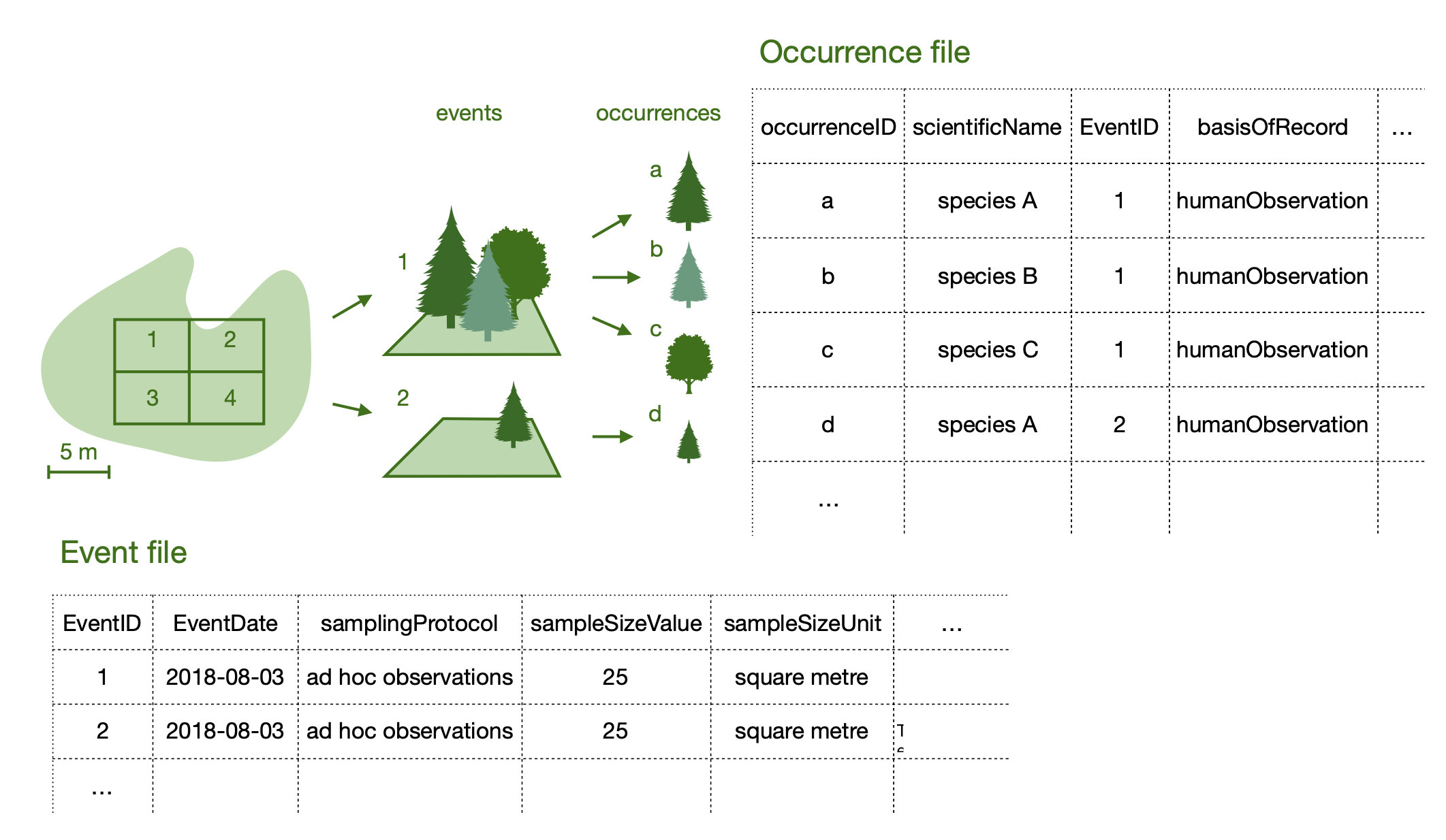
Sampling-event datasets can seem a bit more complicated than other datasets because they need two files:
- One describing events
- One describing the occurrences associated with each event
Each occurrence is linked to its event thanks to the eventID columns. The example below illustrates how sampling-event datasets are structured.
Conclusion
I hope this short guide is useful. Don’t hesitate to browse the datasets available on GBIF and check what other data providers chose.
If your data cannot fit into any of the classes supported by GBIF, please leave a comment or send an email to helpdesk@gbif.org.