GBIF download trends
Explanation of tool
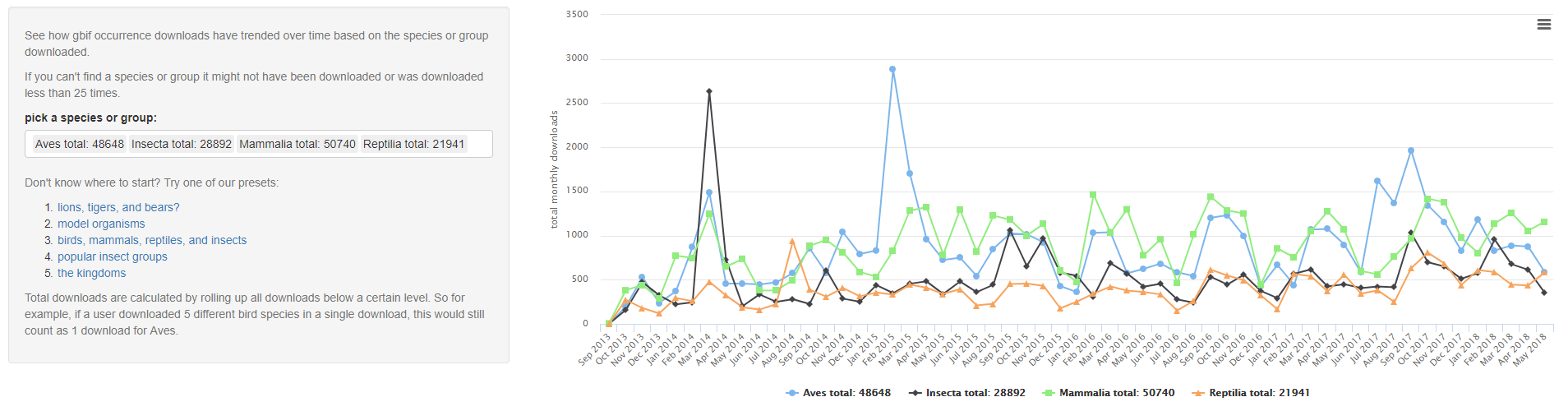
This tool plots the downloads through time for species or other taxonomic groups with more than 25 downloads at GBIF. Downloads at GBIF most often occur through the web interface. In a previous post, we saw that most users are downloading data from GBIF via filtering by scientific name (aka Taxon Key). Since the GBIF index currently sits at over 1 billion records (a 400+GB csv), most users will simplying filter by their taxonomic group of interest and then generate a download.
How to bookmark a result?
If you would like to bookmark a result or graph to share with others, you can visit app page direcly: app link. On this page the state of the app will be saved inside the url.
What counts as a download?
For the graphs above, I decided that it would be more meaningful to roll up downloads below the queried taxonomic level.
- If a user downloaded 5 different bird species as once, this would count as 1 download for Aves and 1 download for each of the species downloaded.
- If a user only typed in Aves in the occurrence download interface and not any other species. This would only count as 1 download for Aves and 0 downloads for all bird species.
- Similarly, if a user only typed the order Passeriformes into the search, this would count as 1 download for Passeriformes and 1 download for Aves, but 0 downloads for all the species, families, and genera within Passeriformes.
It is possible, but not as easy, to get data from GBIF without generating a download. In fact users can stream data using the GBIF occurrence api without ever generating a download. Currently users can “download” 200k-long chunks of occurrence data without generating a download by using the api. This can be done in rgbif.
rgbif::occ_search(taxonKey=212, limit=200000) # get the first 200k records of Aves
If someone got their data using the api in this way, we would not be able to track it currently. Presumably, though, the large majority of users are getting their data directly through the web interface.
How did I get the download data?
Since 2013, GBIF has been tracking, user download filters in the so-called GBIF registry. This data is in fact publicly available via the GBIF registry api. Unfortunately, the data is exported in json and difficult to parse. For example, one could get the download activity on AntWeb by using the following rgbif command:
rgbif::occ_download_dataset_activity("13b70480-bd69-11dd-b15f-b8a03c50a862")
But this would not be a practical way to get all of data for all downloads happening at GBIF, even though it is techinically possible. Fortunately, since I am employed at GBIF, I have direct access to the tables within the registry database. However, it was still necessary to parse the json within the regsitry table. This was no easy task but was made easier by the tidyjson package.
Technical details
- Obviously this app was built in Shiny. You can see the code that generated this app here.
- I am hosting the app on a person Digital Ocean server rather than at https://www.shinyapps.io/.
- The graph is generated using the highcharter package.
- The data is not live. Results are coming from a canned csv compiled in May of 2018.