GBIF attempts to improve identifier stability by monitoring changes of occurrenceIDs
Since 2022, GBIF has been monitoring changes of occurrenceIDs in datasets to improve the stability of GBIF identifiers. We pause data ingestion when we detect more than half of occurrence records in the latest version have different occurrenceIDs from the previous version (live on GBIF.org). This identifier validation process automatically creates issues on GitHub and GBIF helpdesk will contact the publishers to verify the changes of occurrenceIDs.
Our aim in this process is to minimize the changes of GBIF identifiers and to support the needs for citations and data linking. In this blog post, we explain some background information on identifier stability, how we manage GBIF identifiers by occurrenceIDs and what options we can take for identifier issues.
What are GBIF identifiers? Why is it important to keep them?
Once datasets are registered to GBIF, a unique gbifID (numeric string such as 1676099845) is assigned to each occurrence record to create a URL like https://www.gbif.org/occurrence/1676099845. Even though these identifiers are not designed to offer persistent identifiers in the first place, these URLs are used for citing individual specimen or observation records outside GBIF services, for example in Bionomia. We would like to prevent loss of links as much as we can, to support citations. More details on demands towards GBIF identifiers are introduced in this news item. Thanks to efforts and collaboration with publishers toward this project, the percentage of occurrenceIDs that changed in specimen records has dropped from 3.75% (2021-2022) to 1.39% (2022-2023) as reported in the 30th meeting of GBIF Governing Board (GB30).
GBIF identifier management depends on occurrenceIDs
GBIF identifiers (i.e. gbifIDs) are automatically created by our system, using occurrenceIDs provided by publishers. occurrenceIDs are the keys for the relationship between the existing records available on GBIF.org and the updated records in the latest version on the hosting web services. This means that if occurrenceIDs change, we won’t be able to relate them. When a record has a new occurrenceID, we treat the record as a “new” record and assign a new GBIF identifier. The record with the old occurrenceID (that exists on GBIF.org but not in the latest version on the hosting web services) will be considered deleted from the dataset, so the URL of the record will be deprecated like this occurrence.
See the figure below which is an example of updating a dataset (such as a change of catalogue numbering system).
- Top example (no changes of
occurrenceIDs): The URL of the occurrence will remain the same. - Bottom example (changes of
occurrenceIDs): A new URL will be issued for the updated data and the old URL will be deprecated.
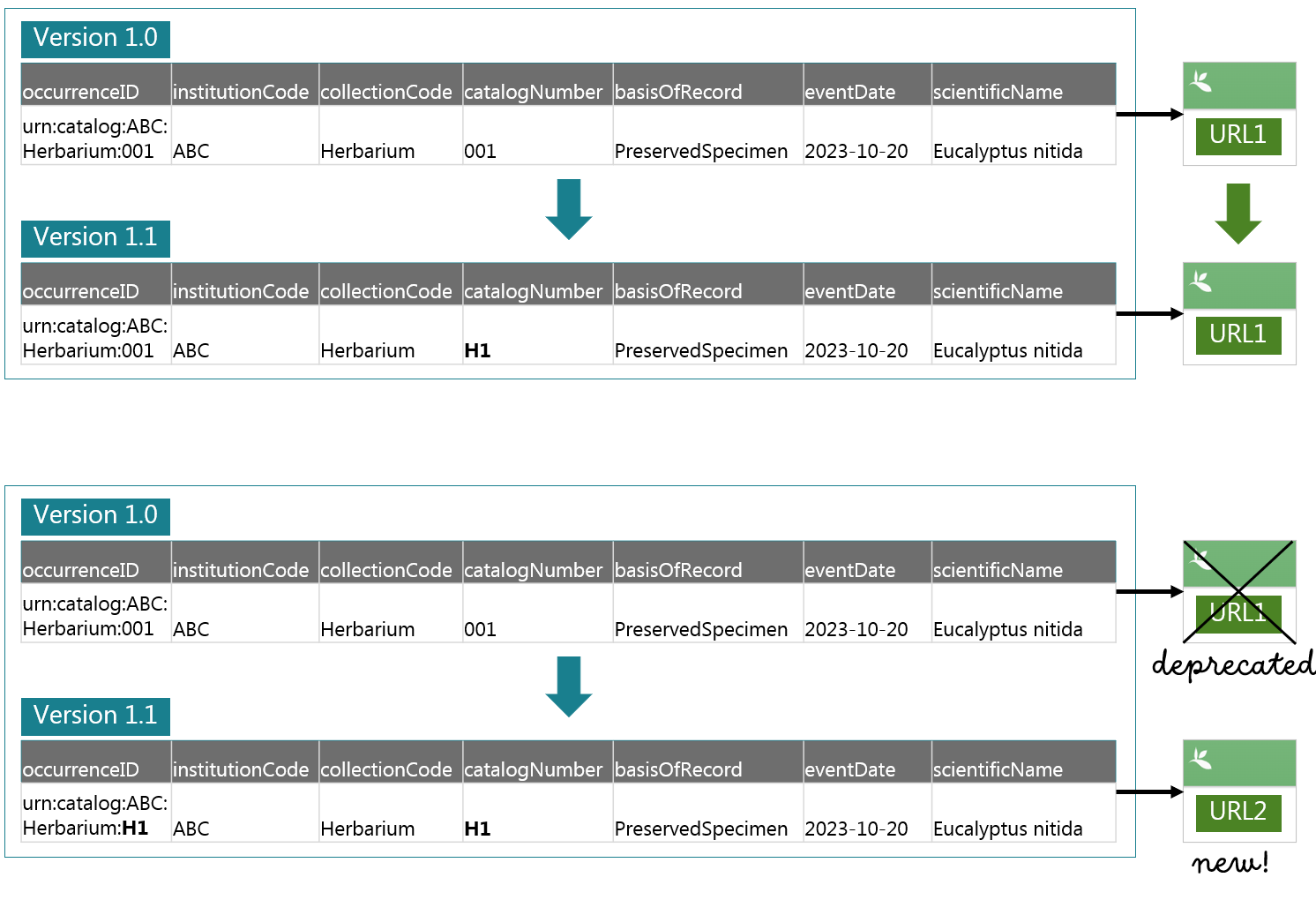
The example above uses a so-called “triplet”, the combination of the institutionCode, collectionCode and catalogNumber for occurrenceIDs (such as urn:catalog:UWBM:Bird:89776). However, using meaningless string or integer values is generally recommended for IDs. Currently there are no strict rules for occurrenceIDs aside from the uniqueness within a dataset. After the discussions with our community (such as this GitHub issue), GBIF has moved towards recommending meaningless occurrenceIDs to promote persistent identifiers. A globally unique identifier such as UUID (e.g. 000866d2-c177-4648-a200-ead4007051b9) can be one of the best practices as recommended by TDWG here.
Please do not worry if you have already used the triplet or other meaningful content for occurrenceIDs in your published datasets. In case you change occurrenceIDs, there is a way to migrate gbifIDs and URLs from old occurrenceIDs to new occurrenceIDs which will be more explained in the following sections.
Note: If you change
catalogNumber, the formercatalogNumbercan be filled out inotherCatalogNumberswhich is used for data-clustering (see this blog post).
Three options to deal with identifier issues
Data ingestion initiates after publishers update and publish a dataset on hosting web services. During the identifier validation, the system counts occurrence records and checks the portion of new occurrenceIDs. If this exceeds 50% of the record count, the data ingestion will be paused creating an issue on GitHub on a per-dataset basis.
We offer three options to deal with the identifier issues.
| Number | Option | Who can do this | What happens after |
|---|---|---|---|
| 1 | Resume the data ingestion by allowing changes of occurrenceIDs |
GBIF helpdesk | GBIF identifiers under old occurrenceIDs will be deprecated and new GBIF identifiers will be given for new occurrenceIDs. |
| 2 | Change back occurrenceIDs (i.e. restore the old occurrenceIDs) |
Publishers | Data ingestion will be automatically resumed after publication and GBIF identifiers remain the same. |
| 3 | Migrate GBIF identifiers from old occurrenceIDs to new occurrenceIDs |
GBIF helpdesk * | Data ingestion will be manually resumed and GBIF identifiers remain the same. |
* Publishers need to provide a list
GBIF helpdesk consults with publishers to decide which option suits the dataset best. Option 2 and Option 3 could prevent losing the URLs of occurrences, while Option 1 leads to the loss of the URLs.
Firstly, we ask whether the change is on purpose or unintentional errors. If the changes of occurrenceIDs are errors, Option 2 can be a candidate solution. What publishers need to do here is to change back from the new occurrenceIDs to the old occurrenceIDs and to publish the datasets on the hosting web services.
Secondly, we suggest Option 3, if publishers can provide us with the relationship between the old occurrenceIDs and the new occurrenceIDs. Using the list of occurrenceIDs, we can migrate GBIF identifiers and keep the URLs (see the figure below).

Once we know that both Option 2 and Option 3 are not feasible, we will take Option 1 to resume the ingestion.
Please be aware that we may take Option 1 if we don’t hear back from the publishers for more than two months after the first contact. We are happy to extend this timeframe on request.
There are cases that identifier issues can be ignored. For example, when the number of occurrence records changes massively, the portion of new occurrenceIDs may reach the threshold. If we can tell an increase of records (like doubled or tripled) by looking at hosting web services such as IPTs, we take Option 1 without notification. Another example is the datasets from observation data aggregators in which occurrenceIDs always change. In this case, we set a flag to skip occurrenceID checks for these datasets, and data ingestion will not be paused during the identifier validation anymore.
Requirements for identifier migrations
For migrating GBIF identifiers, a list of the relationship between the old occurrenceIDs and the new occurrenceIDs is required. The file has no header in a comma delimited format, and it should contain the old occurrenceIDs in the first column, followed by the new occurrenceIDs in the second column. For example, like this:
old_id_00001,new_id_00001
old_id_00002,new_id_00002
old_id_00003,new_id_00003
If publishers can send a list to GBIF helpdesk (helpdesk@gbif.org), we can run an identifier migration for you. This can be done even before publishers update datasets on hosting web services. If you know occurrenceIDs change in the next update, please do not hesitate to contact us.
Another important note here is that migration can be done between datasets. If you are planning to republish occurrence records in new datasets by removing the records from the previous datasets or deleting the datasets themselves, this approach will help maintain the GBIF identifiers for the records. The URLs in the previous datasets can be used in the new datasets by identifier migrations anytime.
More information for publishers: how to detect identifier issues on the GBIF registry.
GBIF helpdesk will contact the publishers when identifiers validation fails, but you are welcome to check the GBIF registry on your own.
You can access the registry from your dataset page on GBIF.org.
Look for GBIF Registry link in the GBIF registration section.
On the registry page, Click Ingestion history under the Datasets in the side menu.
If VERBATIM_TO_IDENTIFIER : More than one metric is in red characters, this means that the identifier validation failed (a big portion of new occurrenceIDs were detected).
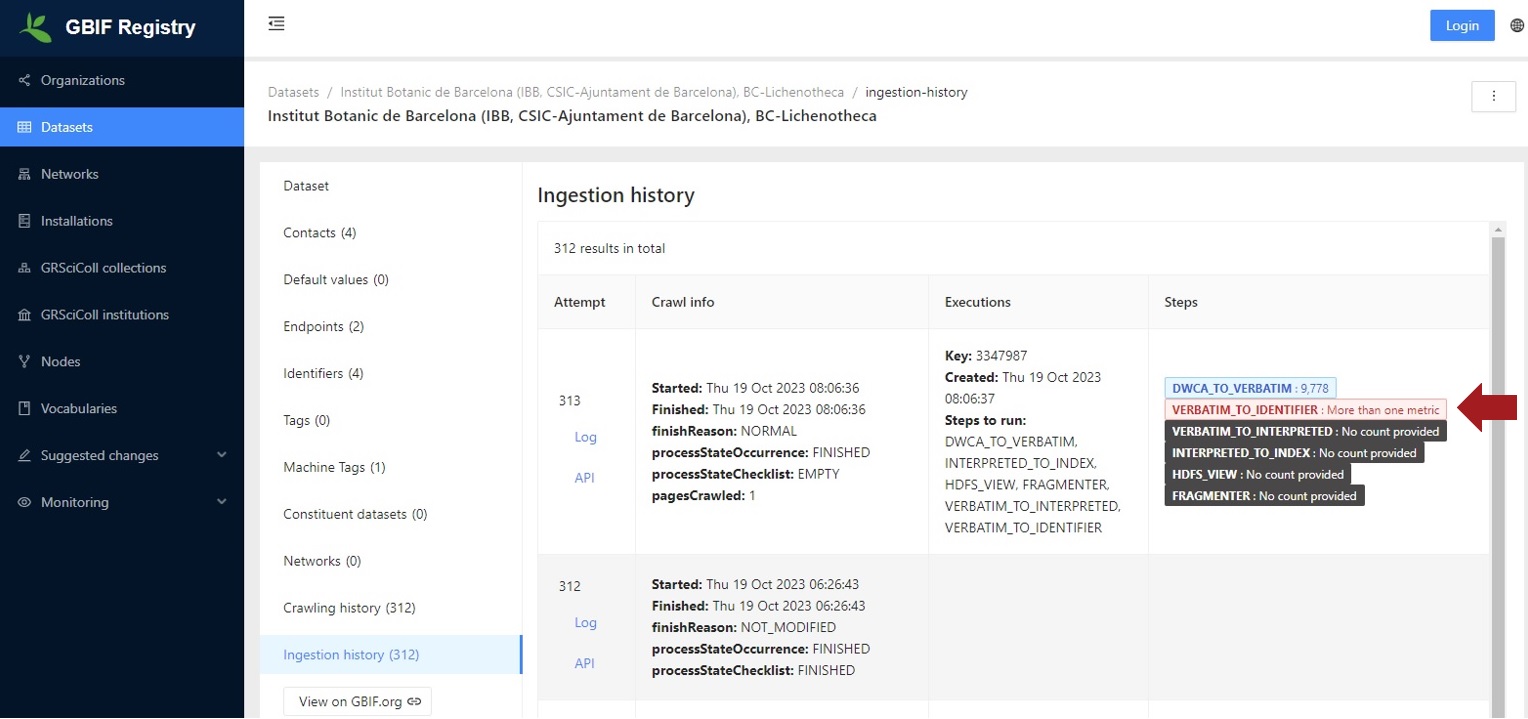
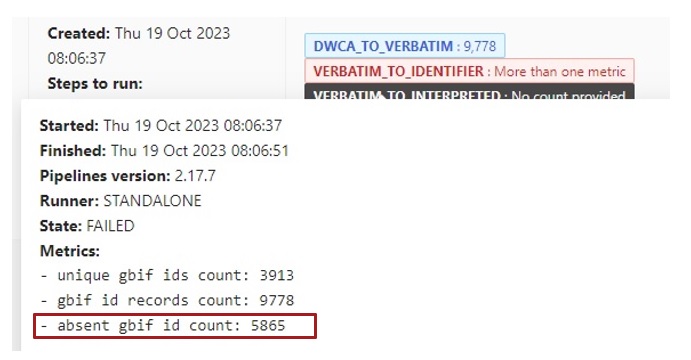
If you hover on VERBATIM_TO_IDENTIFIER : More than one metric, you can see a record count in the metrics.
The record count for new occurrenceIDs is shown in the absent gbif id count.
You can also check whether your dataset has identifier issues on GitHub searching by the dataset title.