Gridded Datasets Update
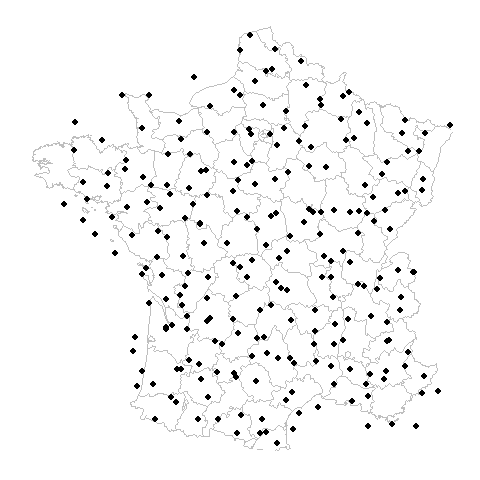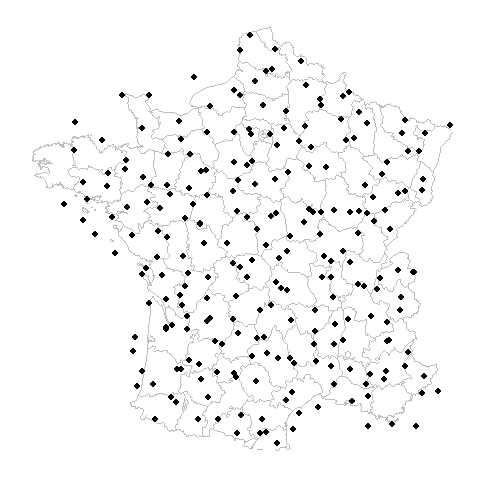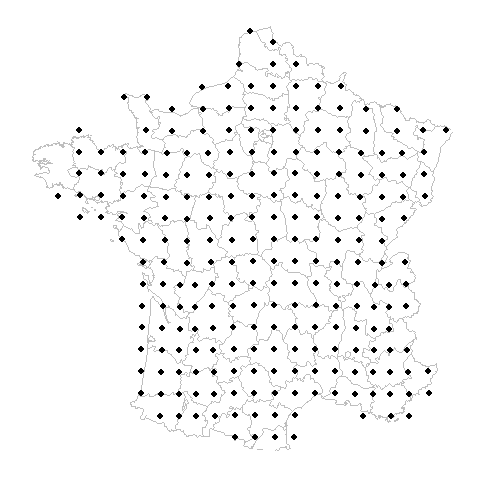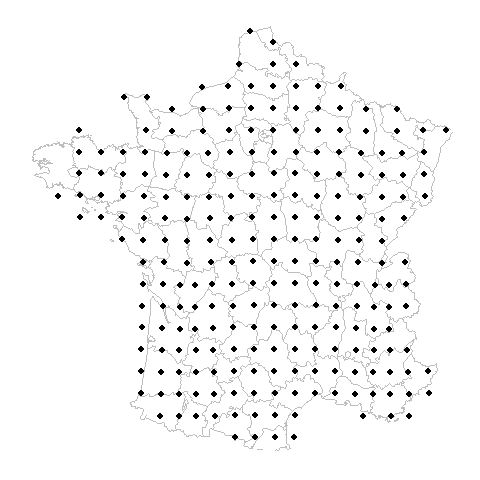
Gridded datasets are now flagged on the GBIF registry
This update builds on work from a previous blog post.
Gridded datasets are broadly datasets that have low coordinate precision due to rasterized sampling or rounding. This can be a data quality issue because a user might assume an occurrence record has more precision than it actually does.
Current statistics
- 572 datasets are currently flagged as gridded or rasterized on the registry.
- 488 of these are regularly spaced at 0.1 decimal degrees (around 10 km)
- 40 datasets are regularly spaced at >0.1 decimal degrees example
These final 40 datasets with very large spacing are probably of most concern to those needing precise location information.
What datasets were flagged?
- Datasets with >20 unique lat-lon points.
- Datasets that have >30% of their unique lat-lon points with the same nearest neighbor distance
- Only datasets with a nearest neighbor distances >0.02 decimal degrees were flagged.
- WGS84 is assumed to calculate distances in decimal degrees.
- All unique occurrence points from each GBIF dataset have been used this time. This means I was able to flag more datasets.
How can this information be used?
The current algorithm for detecting gridded datasets relies on nearest neighbor distances between unique occurrence points. This is described in more detail in a previous post.

This produces a simple measure of distance in decimal degrees that can be used for filtering out datasets that might have a coordinate precision above what is expected from the study. The following api call will get all of the datasets flagged as “gridded” in the GBIF registry.
http://api.gbif.org/v1/dataset?machineTagNamespace=griddedDataSet.jwaller.gbif.org&limit=1000
Such an api call could be easily incorporated into R packages for data cleaning, such as CoordinateCleaner. In the meantime, I have created a simple function to extract gridded dataset keys from the registry. The following will install a package that can be used for extracting flagged datasets from the registry.
# Installation
devtools::install_github("jhnwllr/griddedDatasets", subdir="gbifgridded")
You can now use the gbifgridded::getGriddedKeys function to filter out low resolution datasets.
library(rgbif)
library(dplyr)
# taxon key for Syntrichia norvegica Weber, 1804 (a moss)
taxonKey=2671266
# Get occurrence data for a moss occurring in SWEDEN
occData <- occ_data(taxonKey=taxonKey,
country="SE", # get only from SWEDEN to limit results
hasGeospatialIssue=FALSE, # remove those with other geospatial issues
hasCoordinate=TRUE, # get only with coordinates
limit=1000)$data # get first 1000 records
# only get dataset keys with spacing greater than around 10 km
keysToFilter <- gbifgridded::getGriddedKeys(minDistance = 0.1)
nrow(occData)
cleanData <- occData %>% # should be around 140 occurrence records
filter(!datasetKey %in% keysToFilter)
nrow(cleanData) # should remove around 50 low resolution occurrences
You can also run the function with no arguments to get a list of all the datasetkeys that are gridded.
gbifgridded::getGriddedKeys()